Loading the dashboard with more than 2 goals in "goal overview" widget is very slow because of update query #15579
Comments
|
@peterbo I suppose browser archiving is enabled? |
|
@tsteur Hey Thomas! No, disabled in all instances. Also purging archives / raw data is not active.
|
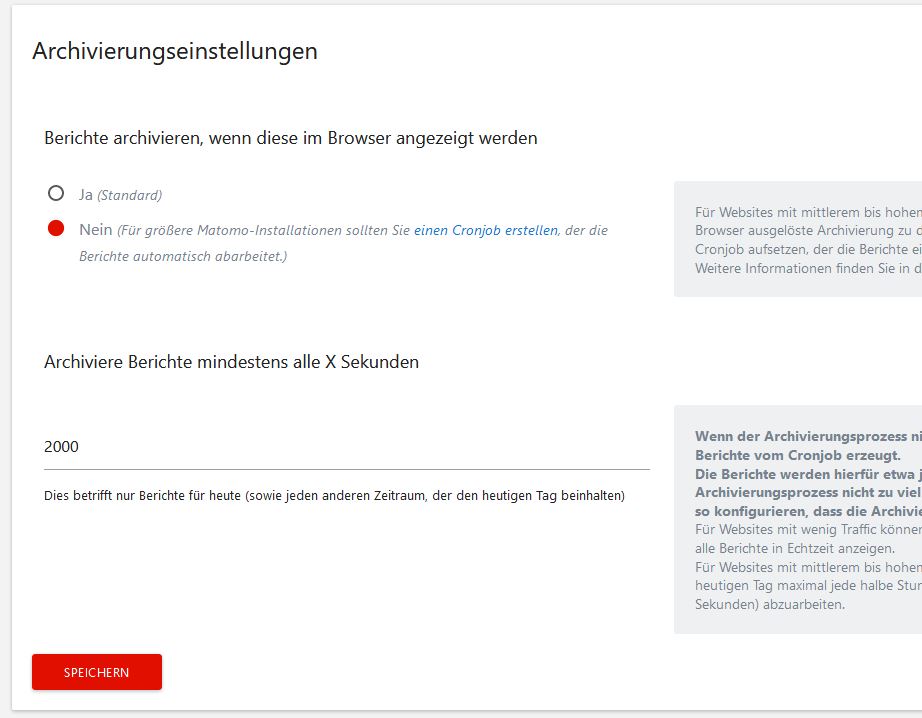
|
Seems like this has been reported before: #7195 (for blob tables) |
|
@peterbo are there maybe ranges viewed or so? Or a segment selected? Cause generally it should not trigger these methods as far as I can see. |
|
@tsteur I was wondering about that too, but it's a normal "all visitors" setting for a single day (doesn't matter if you include the current date or not):
Could this be caused by a (premium) plugin? This would be something that all my tested instances have in common. (e.g. Cohort, CustomReports, Heatmap, FormAnalytics) |
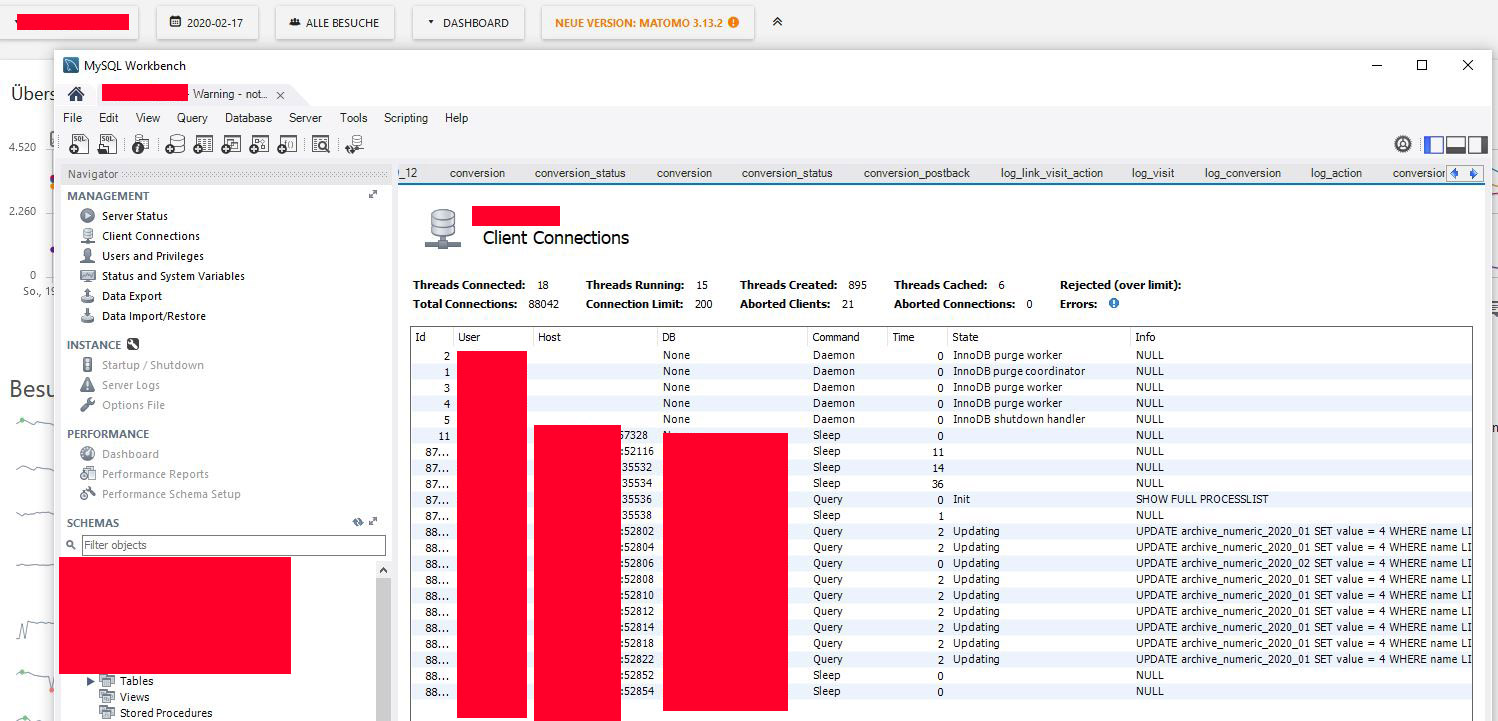
|
I created another, easier testcase: A Dashboard only with the Goal overview report. You can see how long the queries are running (because they're blocking each other) and that the widget is still loading as long as the queries take to execute:
But it seems that also (probably) sparklines and/or graphs in general are issueing these queries, because I can find them in the processlist with only the Visitor overview widget on the dashboard. |
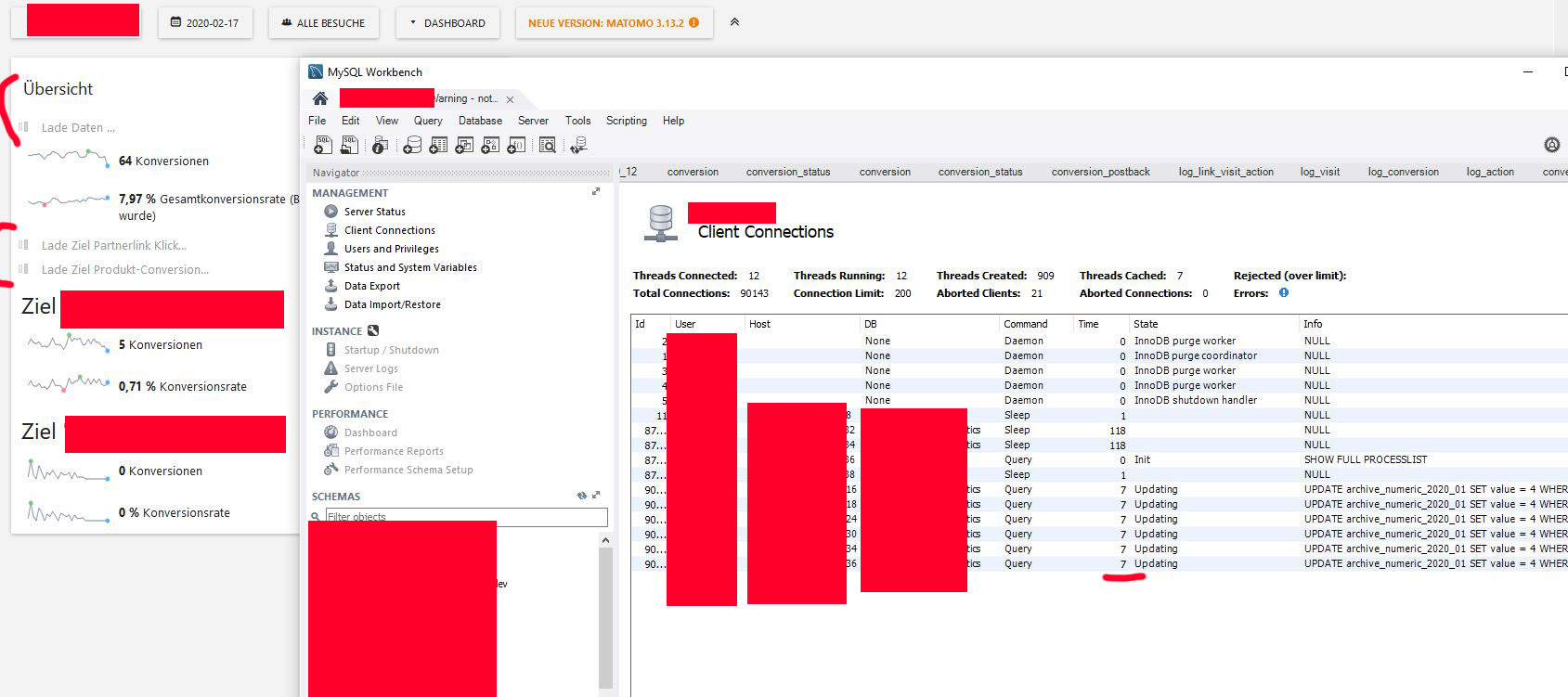
|
I can reproduce it. To reproduce it issue a tracking request, and then open eg a goal sparkline eg https://example.com/index.php?forceView=1&viewDataTable=sparkline&module=Goals&action=get&idGoal=12&allow_multiple=0&only_summary=1&widget=1&containerId=GoalsOverview&idSite=1&period=day&date=2020-01-19,2020-02-17&segment=&showtitle=1&random=3861&columns=conversion_rate&colors=%7B%22backgroundColor%22%3A%22%23ffffff%22%2C%22lineColor%22%3A%22%23162c4a%22%2C%22minPointColor%22%3A%22%23ff7f7f%22%2C%22maxPointColor%22%3A%22%2375bf7c%22%2C%22lastPointColor%22%3A%22%2355aaff%22%2C%22fillColor%22%3A%22%23ffffff%22%7D Make sure to have a breakpoint at the It likely regressed by What happens is it calls These segments aren't preprocessed so as long as browser segment archiving is enabled (which it usually is) it will launch the archiving and part of this invalidate all reports.
This was always an issue. However, in 3.12 we started invalidating reports for today. This means whenever there is a request for today, a report will need to be invalidated and the mentioned queries are executed. So for people that were importing visits for previous day this was already a problem. But now this is a lot more severe cause we invalidate for today's report so every time a new tracking request comes in, it will execute these queries again by the looks. I suppose a workaround for now be to configure these segments in The disadvantage being that it will generates archives for all reports for these segments and not just the goal reports. Not sure how to fix this issue in general yet. If browser archiving is disabled, an easy fix could be to not invalidate reports in a regular request. However, for segments we typically would want to invalidate these reports even during a regular request. I suppose, during a regular web request, we could only execute the invalidation logic if there is a report to invalidate for the selected date. Then people would still have the problem for today though. Will need to see how to best fix it. |
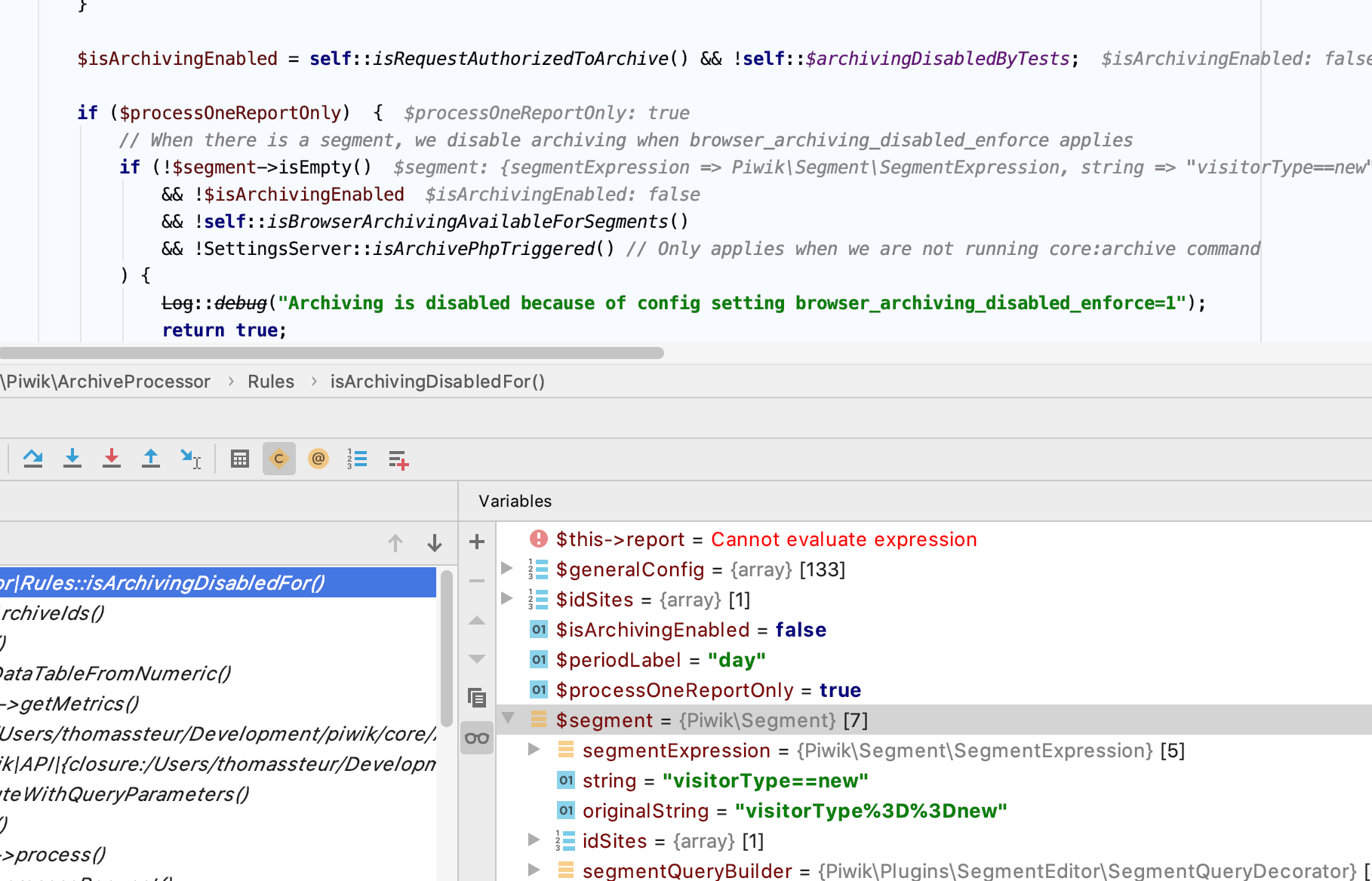
|
@tsteur could we create some mechanism to perform this logic after the HTTP request is finished? eg, like using |
|
@diosmosis |
This would potentially do the trick I reckon and also fix it for MediaAnalytics etc |
|
We don't invalidate for specific segments right? If not, then that should work 👍 |
|
👍 |
|
@tsteur started looking into this and noticed there's some code there already that ensures invalidation for the same idSite only happens once per request: https://github.com/matomo-org/matomo/blob/4.x-dev/core/Archive.php#L488-L492 . can you confirm that's what the code is supposed to do? |
|
@diosmosis that's generally good 👍 In this case it's though about not launching it at all if we are currently in |
|
@tsteur do you mean not launching archiving at all? or archive invalidation? If archive invalidation, then the code I linked to should have the same effect, shouldn't it? Ie:
|
|
@diosmosis I actually wonder if that even made sense what I said. Looking at it again the moment this invalidate method is called, we might actually not even be within The goal be yes to not even launch archiving when browser archiving is disabled because we're archiving for Not sure if / how this can be avoided. I suppose something like this be rather a hack but also can't think of anything else right now in https://github.com/matomo-org/matomo/blob/4.x-dev/core/Archive.php#L618-L624 if (isBrowserArchivingDisabled() && !isArchiveTriggered() && in_array('Goals', $plugins) && in_array($segment, array($newVisitSegment, $returningVisitSegment))) {. //do not launch archiving } |
I still don't think I'm clear on the issue here. If browser archiving is disabled, then we currently don't launch archiving at all in Archive.php. So the code should never get to |
|
It executes this API call which has a segment returningVisit or newVisit attached. It goes then into the |

|
I see, the API call triggers multiple Archive queries... ok, well, it's a lot easier to solve when we know where the actual problem is :) |
|
Is it just invalidation that causes the issue? We could simply disable invalidation if the Archive object has a segment, but the root query doesn't have a segment. Ie, if |
|
I'm not sure. We might still need to invalidate archives when there is a segment as otherwise user might get an outdated report?
I see maybe like this it could work 👍 |
|
Actually that won't work either for the same reason as before, https://github.com/matomo-org/matomo/blob/4.x-dev/core/Archive.php#L456 should save the idSite in the list as already processed, then when the next archive query is run, the invalidation will be skipped. This issue probably needs some more investigation. |
|
I suppose this might be fixed with #15616 Moving it into 3.13.5 so we can confirm it there. It would be still an issue if someone is tracking regularly historic data for previous days but this would have always been an issue before as well. |
|
@peterbo Can you still reproduce this issue with 3.13.4? |
|
Hi @tsteur I wasn't able to test the update with the affected instances yet unfortunately, as these are heavily dependent on the user-ID feature that would be affected by the update. Perhaps I could do an update while manually implementing a fix for our user-ID use case. I'll clarify with the customer whether this would be an option for them and report back here! |
|
@peterbo wondering if we can close this issue now? |
|
Hey @tsteur - It is still consuming a lot of CPU power and and temp tables, but it is much better than it was before. The problem with testing is, that most of the instances in question (where it was extremely slow) are still running on pre 3.13.4 versions, so I wasn't really able to test the behaviour of the instance, mentioned in the initial post. But in other instances, things have been better since. |
|
👍 @peterbo I'll close this for now and we can always reopen when/should it become an issue again. |
|
@tsteur - now one of the bigger instances was updated from 3.x to 4.2 and the difference in loading time with many goals is huge. Not saying that there aren't other things that could be optimized in the future, but now, working with bigger dashboards is a lot quicker. Thank you! |
|
Awesome @peterbo that's great to hear |
Loading the dashboard with the All Goals report (with more than 2 goals) can take quite some time. This has been getting worse since the 3.12 release.
I notice a lot of queries like this when refreshing the dashboard:
UPDATE archive_numeric_2020_01 SET value = 4 WHERE name LIKE 'done%' AND idsite IN (195) AND (((date1 <= '2020-02-17' AND '2020-02-17' <= date2)))One dashboard refresh seems to trigger dozens of these requests with some of them take 5+ seconds to finish (probably because of locking).
SELECT count(*) FROM archive_numeric_2020_01 where name LIKE 'done%'shows that there are more than 100k rows that have to be checked for updating, which seems quite inefficient.This seems to be triggered in the function updateArchiveAsInvalidated to clear overlapping archives. Can this be moved to being done asynchronously via cron?
The text was updated successfully, but these errors were encountered: