Allow plugins to generate their reports using historical data (eg. Custom Reports) #11974
Comments
|
When I create Custom reports, and want historic data, I need to invalidate all historical data, and re-process them. It can takes a very long time and is not practical. Recently we had a problem around too much data invalidated (reported in innocraft/plugin-InvalidateReports#8). So it will be great to have the ability to "update" existing archives and process the data for specific plugins (eg. custom reports) without having to re-process everything else. |
|
Note: this will be also especially important and valuable for Matomo Cloud service customers where invalidating old data is currently disabled, So users who create custom reports cannot get historical data for their custom reports. Whereas for self-hosted users they can at least manually invalidate reports. |
|
Hi, I'm wondering if this is still planned as part of 3.12 or 3.13? Thanks. |
|
I reckon this will be part of Matomo 4 which we might work on after 3.12 but to be seen. This is definitely an issue we want to work on! In the meantime we created a command that let's you get this data quite easily. If you have access to the command line, you could simply execute Here's an example
There are various options (eg not for segments, only specific periods, ..) and using the latest custom reports you can even do this only for a specific report using It's quite fast to archive these reports in the past. |
|
@tsteur , Thanks for the update. Is the below available in 3.11 ?
Thanks a lot. |
|
Yes this works with 3.11 . It's in the custom reports plugin |
|
Thank you. That helps. Can you also confirm if this has an equivalent for webAPI? Believe all the console commands have equivalent Web-Based API calls, to make sure this can be done with browser based instead of console. |
|
There is no API unfortunately as it's working bit differently from the other features. |
|
Hello @tsteur . Sorry for getting back to you on this late. Validated this in 3.11 version and I don't see this parameter being available in the help documentation. Here is the screenshot for your reference.
For #1 command: 3.11 is the Matomo version For #2 command: missing --idreport parameter from the help documentation For #3 command: Custom Reports archiving failing for the usage of --idreport We have also updated the latest version of custom reports plugin, just to make sure we are not in the old one - (latest available - 3.1.18). Please let me know if I am missing something here. Thanks a lot. |
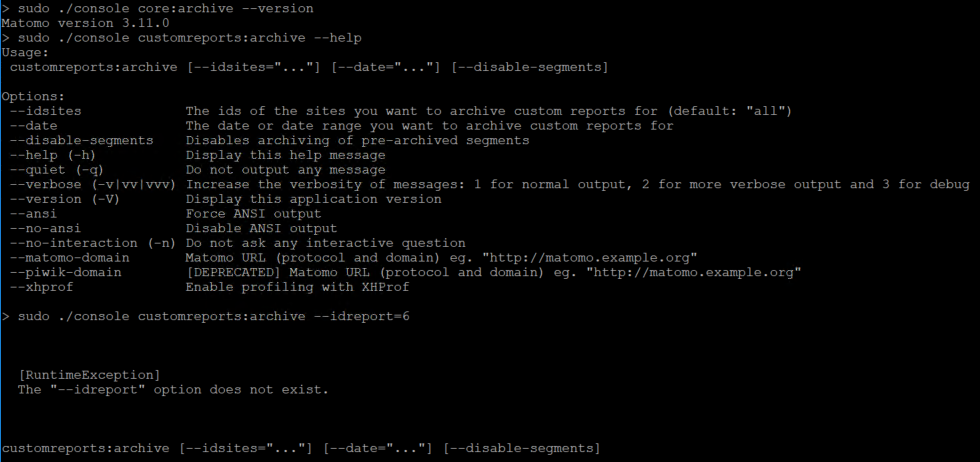
|
@siva538 it looks like you're not using the latest version of custom reports for some reason. It should definitely have the parameter. |
|
@tsteur , was able to finally get the parameter to working. Thank you!. Turned out to be a caching issue. Can you please confirm if 3.1.18 is mandatory for this or is available in 3.1.15 as well for the custom reports plugin? Thanks a lot. |
|
I think it was added in |
|
Thank you @tsteur |
|
@tsteur I'm going to base this issue's solution off of #15117, and go about it like so:
Do you see any potential issues w/ this plan? |
|
@diosmosis hard to say. I suppose we'd need specific done flags for all plugins and basically create an archive for each plugin and basically no longer use a generic I suppose ideally this would work for any plugin where data can be generated retrospectively. Especially interesting for Funnels and Custom Reports I guess. The goal has to be as soon as a new custom report is created, the system would basically notice either through browser archiving or cron archiving that an archive for a specific custom report is missing, and would start archiving these reports. I suppose technically we'd even want this feature should a custom report be updated then indeed we would likely invalidate these plugin specific archives (but not invalidate other data). They don't have generally a #15117 maybe it would make sense to have a separate table for archive invalidations and no longer handle invalidations in the archive table directly but hard to say (I suppose we'd still need to handle a flag whether a specific archive is invalid or not). Wonder if a table like
All I can say really is how it should work generally from a user point of view. Hope this helps. |
This is sort of my approach, allow invalidating individual plugin archives, then plugins would just invalidate archives and they would get picked up by core:archive.
This could be a good idea maybe... though we'd have to query the table when querying for archive data when browser archiving is enabled. In that case we wouldn't want to use archive data that is invalidated. |
|
@tsteur what do you think about using an invalidations table like: The other columns are needed in order to be able to sort the table properly w/o having to look at an archive table simultaneously. Otherwise we'd have to join on an archive table. When browser archiving is enabled we'd have to join on this table by idarchive/name to check if an archive is invalid. We could also limit the number of rows we add to this table. Eg, if there are more than 50000 rows or something, just fail the invalidation w/ a warning requesting users to run core:archive. Though this could be an issue for browser archiving... since the user might invalidate an archive then never view it? I guess we could do both and only add to the table if browser archiving is disabled. This would make the implementation more complicated, but might be worth it if the cost goes down? |
|
I reckon a limit shouldn't be needed, but it be awesome that we could show this in the UI. Meaning the number of archives that are invalidated and will need to be reprocessed, and we could even show which reports will be archived soonish. BTW on the |
|
Haven't thought too much about it but looks good. BTW the primary index would be probably fine on idArchive alone? |
|
@tsteur If we allow invalidating individual reports/metrics (or just plugins), then we'd have to allow multiple idarchive/name pairs. And there's no issue w/ still doing DONE_INVALIDATED for browser archiving? If we don't then the rows in the invalidated table could just keep building or never be deleted. |
|
I suppose that would be fine considering it's currently the same behaviour (just spread across multiple tables) and we will be trying to get most users to set up cron archiving in a few months (by improving onboarding) |
In Piwik reports are processed based using the raw data. Once an archive has been processed for a website and a specific date period, and stored in the database (during the
core:archiveprocess), it can only be invalidated (via HTTP API or CLI or InvalidateReports plugin) which will force all plugins to re-process all their respective reports in the next archiving process. This is problematic because it can take a lot of time to reprocess previous reports for 3 or 12 months.-> Plugins should be able to easily create their own reports for some of the historical data. this is useful for all plugins which don't create new raw data but re-uses the existing raw data. For example, Funnels plugin would like to process Funnels data in the past 6 months.
To make it possible for any plugin to append their reports to the existing archives, we need to make some changes to the archiving process.
Ideas:
(not related but a bit similar to #7573 )
The text was updated successfully, but these errors were encountered: